ReBAC to the Future! Building Policy on Neo4j Data with Enterprise OPA
Relationship-based Access Control (ReBAC) is a common requirement when applying Policy as Code controls in modern applications. Consider sharing a document with a collaborator in a different organization. As the collaborator is in another organization, it might be hard to grant them a pre-defined internal role without granting more permissions than needed – if indeed an external identity can be bound to an internal role at all. This is where ReBAC comes in.
ReBAC allows for a more flexible permissions model. Roles, defined as sets of permissions bound to users to grant permissions, can become cumbersome when working with dynamic data. While it’s possible to create custom roles to grant granular permissions to users, in larger systems with user defined permissions we quickly run into the problem of users having too many roles and it being expensive to determine permissions in authorization checks. ReBAC allows us to break out of this model and define permissions as edges in a graph instead. For example, a user might have edges to the documents or folders of documents they have access to rather than needing to have all the documents listed in a number of roles.
In this post we’ll dig into ReBAC and see how Neo4j and Enterprise OPA can work together to connect users to the resources they need access to.
What’s Hard About ReBAC?
As far as permissions are concerned, ReBAC can be used to build an entirely new type of authorization model. Perhaps users can only invite friends of friends; or users need to invite whole teams or organizations to view documents – these examples are compelling and increasingly common. Let’s have a think about the challenges these requirements pose.
- Existing Data. Generally, by time you’re investing in a refactoring of your permissions stack your existing data has some inertia. Datasets are often tightly coupled to other systems and are constantly updated, making them hard to re-architect.
- Impatience. Paying Customers and Angry Netizens are generally less patient. While internal users can go get a coffee while their new permissions are rolled out, customers and external users without the same visibility expect immediate updates. This in turn sets requirements on our ReBAC system’s datastore.
- Dynamic Queries. Modeling and querying relationships is the core work of a ReBAC system. While it’s possible to represent relationships in many datastores, we think that for ReBAC it can really pay to use a datastore and query language designed with relationships in mind.
- Existing Policies. It’s common that ReBAC isn’t the only player on the team. ReBAC often arrives as an extension to existing permission models like Role Based Access Control (RBAC) and Attribute Based Access Control (ABAC). It can be hard to deliver this functionality in a single system.
Building ReBAC with Enterprise OPA
It was in the face of these challenges that we recently designed and delivered new ReBAC functionality in Enterprise OPA. This new functionality sets the scene for modern ReBAC through an OPA lens, let’s see how it fares against our challenges from above.
Putting Existing Data to Work – Within Existing Policies
Keen to get ReBAC functionality within reach for users, starting with Neo4j, Enterprise OPA can make use of relational datasets right from Rego via a new built-in function. By directly accessing existing datasets, they can be used to add ReBAC functionality to existing functions without rearchitecting and costly data migrations.
For example, if we had some nodes and edges representing a directory structure like this:
// Nodes
CREATE (user1:User {username: 'user1'})
CREATE (user2:User {username: 'user2'})
CREATE (root:Directory {name: 'root'})
CREATE (dir1:Directory {name: 'Docs'})
CREATE (subdir1:Directory {name: 'SubDocs'})
CREATE (file1:File {name: 'doc1.txt', size: '10KB'})
// Relationships
CREATE (root)-[:CONTAINS]->(dir1)
CREATE (dir1)-[:CONTAINS]->(subdir1)
CREATE (subdir1)-[:CONTAINS]->(file1)
CREATE (user1)-[:HAS_PERMISSION]->(dir1)
CREATE (user2)-[:HAS_PERMISSION]->(file1)
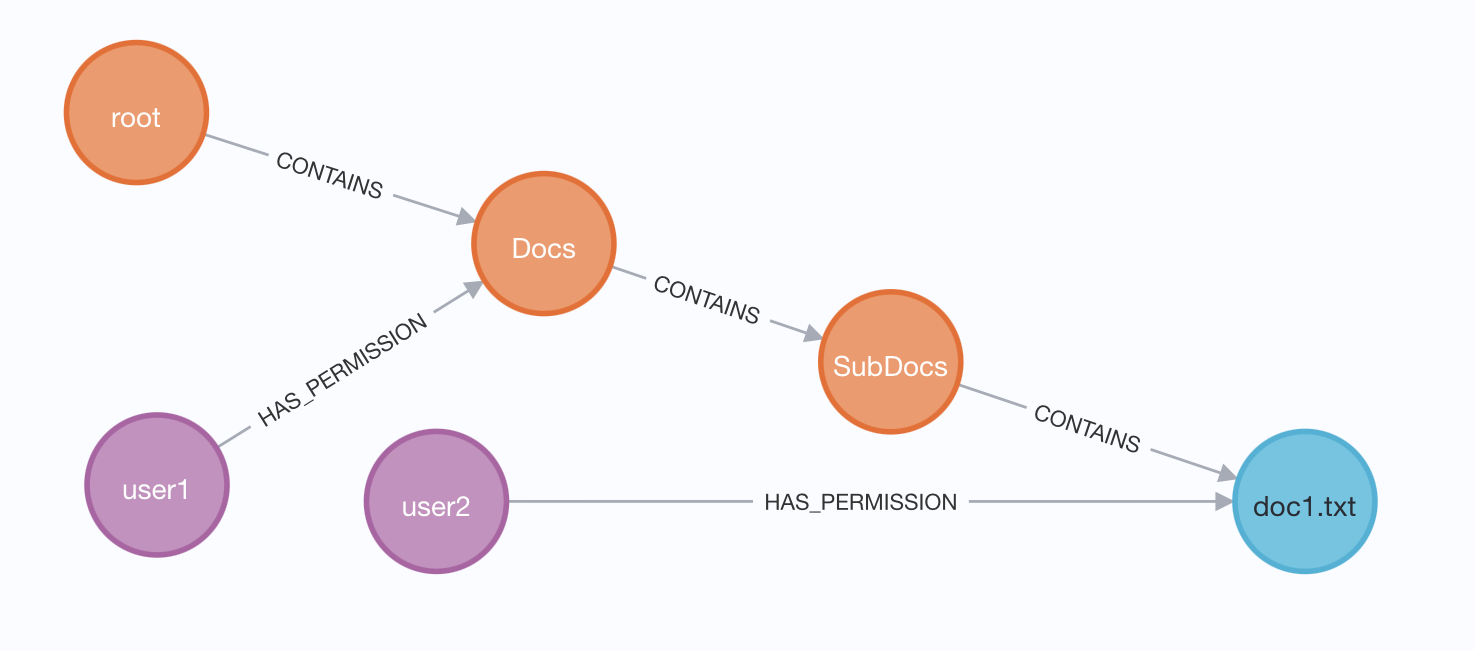
Then it’d be possible to determine that if a user has permission based on their file or directory permissions like this:
MATCH (user:User)-[:HAS_PERMISSION|CONTAINS*]->(file:File)
WHERE user.username = 'userN' AND file.name = 'doc1.txt'
RETURN COUNT(*) > 0 AS hasPermissionIn order to run this query from Rego in Enterprise OPA, we can use the Neo4j.query built in function like this:
queryString := `MATCH (user:User)-[:HAS_PERMISSION|CONTAINS*]->(file:File)
WHERE user.username = $iuser AND file.name = $ifile
RETURN COUNT(*) > 0 AS hasPermission`
request := {
"uri": "neo4j://localhost:7687",
"query": queryString,
"parameters": {
"iuser": input.user,
"ifile": input.file
}
}
# by default, we deny requests
default allow := false
# if there is a hasPermission link, then we allow
allow := neo4j.query(query).results[0].p.Props.hasPermissionWhile this is a simplified example, it shows just how quickly existing graph data can be pulled in to add ReBAC functionality to existing policies.
Punctual Results, Less Impatience
Users expect instant updates. When they’re making changes that impact permissions, users expect instance updates to permissions. While it is feasible to rapidly rebuild policy bundles, there are instances where bypassing this step and directly accessing the source proves even quicker.
We’ve now made this possible in Enterprise OPA with a native Neo4j integration. With Hashicorp Vault integration, read-only transactions, and result caching; based on a native Neo4j client the integration is a robust, production ready system to build a ReBAC permissions stack.
Dynamic Queries meets Dynamic Policy
Neo4j’s popularity stems from its flexibility in querying interconnected graphs of data, offering an efficient way to navigate relationships with Cypher, its declarative query language. Graphs excel in representing varied connections between different types of resources and has become a popular choice in modern applications modeling dynamic and interconnected data.
Over in the land of policy-as-code, Rego, the policy language of OPA, has also seen incredible adoption. Its domain-specific design, readability, performance have all contributed to its success. An often overlooked yet key facet of Rego is its ability to express different access control models.
Let’s imagine we have a user in a group with access to some secret system, but they have to get a new token by completing a 2 factor authentication challenge when they land in a new country. This is an example of an Attribute Based Access Control (ABAC) extension to a more traditional Role Based (RBAC) system. Being able to express dynamic access controls such as this is a key benefit of Rego and OPA.
Adding Neo4j support to Enterprise OPA opens the door to a third model: ReBAC. Our dynamic policy language and now access dynamic datasets stored in Neo4j – we think it’s a great match. Not only does this integration offer users more flexibility, but potentially faster permissions updates too as it’s likely faster to load data from Neo4j than to build that same data into a data bundle — it’s available as soon as the transaction has been committed to the database.
Where Next?
We’re keen to make sure that we can help users build ReBAC policy wherever their data is. The new Neo4j integration joins the SQL and Mongo integrations in Enterprise OPA. We want to work with users to make sure their data sources and requirements are met so reach out if you have any questions to run by us.
If you’re interested in getting hands on with this Neo4j and Enterprise OPA, you can check out the tutorial or dig into the reference documentation for the new function. Keen to chat or get some feedback on a ReBAC design? We’d love to help in the Styra Community Slack. Happy ReBACin’!