Automatic Kubernetes Data Replication with Open Policy Agent
Open Policy Agent (OPA) is widely used to provide security and compliance policy guardrails for Kubernetes. The built-in role-based access controls in Kubernetes are not sufficient for fine-grained policy. OPA is a proven solution for implementing strong, granular policy checks for cluster resources during Admission Control.
OPA users implement fine-grained policy in the form of rules written in Rego, the declarative policy language of OPA. Rules validate the attributes of a Kubernetes resource and make decisions about whether to allow or deny a resource admission to the cluster. With OPA and Rego, we can write many common policy rules, such as:
- Deny a container image unless it is from a known and trusted container registry
- Deny a container if it is configured to run in privileged mode
- Deny an Ingress resource if it is not configured for TLS
These simple, yet powerful, rule examples above only need to check attribute values that are present on the resource at the time of admission. These rules are ‘stateless’ or ‘self-contained’ in a way. They rely only on the policy query input (i.e. the resource object spec) to check if the resource is secure and compliant.
Yet, there are many other types of policy rules that we often want to put in place. For these other rules, the attributes in the resource spec are not sufficient to make a decision. These rules rely on referential data to make an allow or deny decision, such as:
- Deny Ingress Hostname Conflict
- Deny admission of an Ingress resource if the configured hostname conflicts with an existing Ingress resource deployed on the cluster
- Deny Image with Vulnerability
- Deny admission of a container to a production namespace if the image contains known critical vulnerabilities
- Deny Unscheduled Deployment
- Deny admission of a deployment to a cluster if the deployment is attempted outside of a known maintenance window
The italicized text in the above rules emphasize reliance on referential data for that rule. OPA needs to be provided additional data prior to, or at the time of, the evaluation of the policy. For example, to successfully evaluate these rules OPA would need to know:
- The existing set of Ingress resources on the cluster
- The vulnerability report from our image scanning engine
- The maintenance calendar from our release management system
In OPA, we refer to these kinds of referential data sets as External Data.
In this blog series, we’ll explore how to automatically replicate and inject external Kubernetes data into OPA during Admission Control. In this case, you can simply write the policies you want to enforce and Styra software will automatically fetch the relevant data for evaluation.. We will also explore the capabilities of that software, the Styra Declarative Authorization Service (DAS), for the management of policy and external data for OPA.
Replicating Kubernetes Cluster Data into OPA with the Styra Local Plane
The “Deny Ingress Hostname Conflict” rule requires that OPA is aware of all the existing Ingress resources on the current cluster. When a new Ingress is created, the policy can compare the hostname of the new Ingress with the hostname values of the existing Ingress resources. If there is a conflict, then the new Ingress will be denied. This sounds straightforward enough, so how is this done with OPA and Styra DAS?
The OPA documentation for External Data describes five options. These options can be grouped into three categories:
A. Provide external data to OPA as part of the input document during the query (Options 1 and 2)
B. Load external data into OPA’s in-memory data store (Options 3 and 4)
C. Fetch external data in real-time during policy evaluation (Option 5)
Because the data in this case changes fairly rapidly and will fit into the OPA in-memory store, we’re going to choose Category B, Option 4: Push Data. In the case of category A, the OPA user has no control over the input document (it is created by Kubernetes, without data about other Ingress resources in the cluster). Option 3: Bundle API, while valid, will be less efficient in this case (it requires an additional round trip through a central control plane, when the data is already in the cluster, along with OPA).
The OPA documentation for Option 4: Push Data, includes the following diagram showing the role of a “Replicator” component. This component fetches data from a data source and pushes the data into OPA

In the Kubernetes Admission Control use case, the “OPA-enabled Software” is the Kubernetes Admission Control process. And the Data Source is the Kubernetes API Server, as it provides access to the resource data in the Kubernetes persistence store (etcd). Let’s update the diagram with these components:

The “Replicator” can be deployed within the same Kubernetes cluster where OPA is running. The replicator fetches data from the Kubernetes API Server and pushes the data into OPA. The data is then loaded into OPA’s in-memory data store. When OPA is queried the external data is available for use by the policy. (I have also updated the diagram to show Styra DAS, running outside the cluster. DAS provides centralized management for OPA, including the distribution of policy bundles.)
Styra implements the function of the “Replicator” in a component called the Styra Local Plane (SLP). Let’s roll up our sleeves and check out how the SLP works with OPA!
(Note: In the steps below I will be exploring a local minikube cluster into which I have installed the OPA and DAS components. You can follow along with your own Kubernetes cluster. Sign up for DAS Free, then follow the Tutorial to get your own environment up and running.)
The Styra DAS installation manifest for the Kuberenetes system type will deploy OPA as a StatefulSet with 3 replicas. Within a minute or so all 3 OPA Pods will be running on the cluster. The agents will be fully wired into the Kubernetes Admission Control process, and wired into DAS for lifecycle management. Here are the OPA Pods on my cluster:
There are two containers in the READY state in each Running Pod instance. These are the `opa` container and the `styra-local-plane` container:
The `opa` container is running the image built and distributed by the OPA project. The `styra-local-plane` container image is built by Styra for DAS. The SLP is deployed as a sidecar to the primary OPA container. The SLP will fetch Kubernetes resource data from the Kubernetes API Server and push it into OPA via the `PUT` operation on OPA’s Data API.
Optimizing OPA’s Memory Storage for External Data
It would be inefficient for the SLP to read the entire set of resources from the Kubernetes API Server and replicate all into OPA. Even in small cluster environments, the total size of the cluster resources in JSON could be tens of megabytes. This could result in potentially hundreds of megabytes of memory use per OPA.
To minimize the memory consumption, the SLP does not crudely read all the data from the cluster to load into OPA — but only the necessary data. (As they say, “one does not simply load ALL Kubernetes resource data into OPA”). So, how does the SLP know which data is necessary?
Let’s first examine a simple policy that relies on cluster resource data. An implementation of the “Deny Ingress Hostname Conflict” rule (described above) would specifically rely on the existing set of Ingress resources on the cluster. Here is the Rego policy code:
On line 9 of the policy rule, we see the reference to the set of cluster Ingress resources, `data.kubernetes.resources.ingresses`. This is the set of data that the SLP needs to fetch from the Kubernetes API server. Once the SLP fetches the data, it will then push it into OPA’s in-memory data store. Therefore, we need to tell the SLP that this data is necessary. But how?
One option could be for users to manually configure the SLP with a list of resources to replicate. But, we see that these resource references already exist in the Rego code. It would require extra maintenance to configure this list in a second location, external to the code. To avoid this toil we introduced a second key function to the SLP: Rego policy parsing and analysis.
Intelligent Policy Analysis and Dynamic Resource Data Replication
The SLP can analyze OPA policy bundles. Given a bundle, the SLP will identify the Kubernetes resource dependencies within the Rego code. When a dependency is found, the SLP will dynamically update its replication configuration. It will fetch the resource data from Kubernetes and begin pushing the data into OPA. The SLP will also configure a Kubernetes watch on the resource to detect, and then replicate, future changes to the resource. The bundles will now be distributed to OPA through the SLP, to allow the SLP to perform the bundle analysis. Here is an updated diagram representing this new flow:
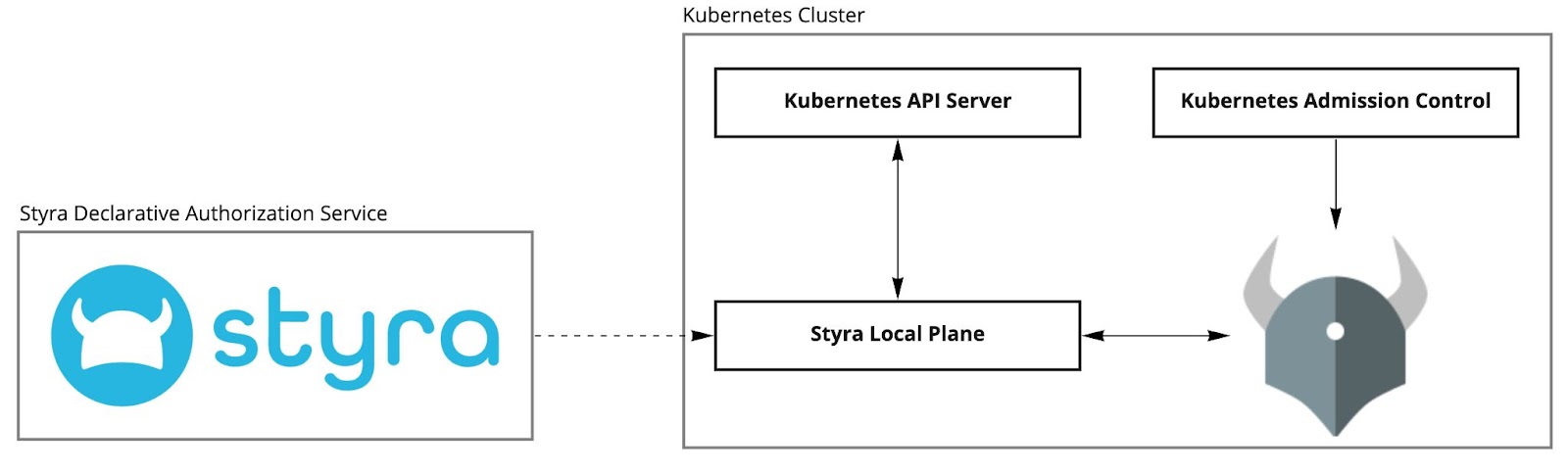
In summary:
- The SLP pulls the policy bundle from DAS
- The SLP analyzes the Rego code within the bundle to identify data dependencies on Kubernetes resources
- The SLP fetches the identified Kubernetes resource data from the Kubernetes API server and pushes the data into OPA’s memory
- The OPA pulls the policy bundle from the SLP to load the Rego policy into memory
- OPA receives queries from Admission Control and returns the appropriate decision
Let’s wrap things up by viewing the OPA logs to see this in action. Start following the opa container logs and filter for PUT calls to OPA’s Data API:
Now, Publish the example Ingress rule from above as a Validating rule within your Styra DAS system. After a few moments (during which the SLP pulls and analyzes the policies in the published bundle), the OPA logs will show that the existing `ingress` data has been pushed into OPA:
If we create a new Ingress on the cluster, the SLP will immediately update OPA (as a Kubernetes watch has been automatically configured for Ingress resources):
We can attempt to create a second ingress that conflicts with the first, but our policy will deny the request:
Finally, while we wrote this policy rule ourselves for this example, when using Styra DAS you would not have to! DAS includes many pre-built policy rules for you to use to implement guardrails for your clusters. You can add the pre-built ingress rule via the “Add rule” option, then select “Ingresses: Prohibit Host Conflicts”.
Summary
In this blog we examined the role of the Styra Local Plane (SLP) component for loading external data into OPA. The SLP performs intelligent policy analysis and dynamically configures itself to replicate only necessary Kubernetes resource data into OPA. From an OPA perspective, this data is pushed into OPA via the Data API (Option 4 – in the External Data documentation).
In upcoming posts in this blog series we will examine the use of other options for integrating external data with our Kubernetes admission control policies. In the meantime, check out Styra DAS Free to begin working with OPA in your Kubernetes clusters!
Read More:
Authorization in Microservices
How to Secure Kubernetes Cluster